Distinguished Paper Award at USENIX Security Symposium 2022
The paper “Dos and Dont’s of Machine Learning in Computer Security”, co-authored by Dr. Fabio Pierazzi, member of the Cybersecurity Group (CYS) at the Department of Informatics at King’s College London, received a prestigious Distinguished Paper Award
The paper “Dos and Don’ts of Machine Learning in Computer Security”, co-authored by Dr. Fabio Pierazzi, member of the Cybersecurity Group (CYS) at the Department of Informatics at King’s College London, received a prestigious Distinguished Paper Award at the USENIX Security Symposium 2022, one of the flagship cybersecurity conferences.


Machine Learning Techniques
Machine learning techniques have led to major breakthroughs in a wide range of application fields, such as computer vision and natural language processing. Consequently, this success has also influenced cybersecurity, where not only vendors advertise their AI-driven products to be more efficient and effective than previous solutions. In security research, machine learning (ML) has emerged as one of the most important tools for investigating security-related problems. Also, many researchers prominently apply these techniques, as algorithms seemingly often outperform traditional methods by large extent. For example, machine learning techniques are used to learn attack tactics and adapt defenses to new threats. However, a group of European researchers from King’s College London, TU Berlin, TU Braunschweig, University College London, Royal Holloway University of London, and Karlsruhe Institute of Technology (KIT), led by BIFOLD researchers from TU Berlin, have shown recently that research with ML in cybersecurity contexts is often prone to error.
Where modern cybersecurity approaches falter
“In the paper, we provide a critical analysis of using ML for cybersecurity research”, describes first author Dr. Daniel Arp, postdoctoral researcher at TU Berlin: “First, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems.” One example of these pitfalls is the use of non-representative data. For instance, a dataset where the number of attacks is over-represented compared to their prevalence in the wild. ML models trained on such data might show different performance when applied in practice. In the worst case, it might even turn out that they do not work outside an experimental setting. Similarly, the results of experiments might be presented in a way that leads to misinterpretations of a system’s capabilities.
In a second step, the researchers conducted a prevalence analysis, based on the identified pitfalls, in which they studied 30 papers from top-tier security conferences published between 2010 and 2020. “Concerningly, we could confirm that these pitfalls are widespread even in carefully conducted top research”, says Prof. Dr. Konrad Rieck, TU Berlin.
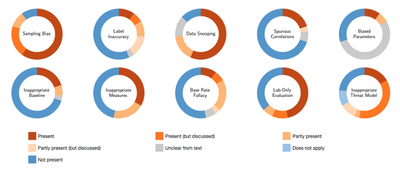
Understanding pitfalls and their prevalence in research is crucial for promoting a sound adoption of learning-based security systems. However, an equally important point is to understand whether such pitfalls, prevalent in all the surveyed research, affect models’ performance and interpretation. This impact analysis on four representative case studies, based on examples taken from the literature, highlighted pitfalls can indeed lead to unrealistic performance and misleading findings. One of the examined case studies deals with the detection of mobile malware. Due to the large number of new malicious apps for mobile devices, traditional anti-virus scanners often have problems to keep up with the evolution of malware and only provide poor detection performance. To cope with this problem, researchers suggested and developed learning-based methods that can automatically adapt to new malware variants.
“Unfortunately, the performance of the learning-based systems might have been overestimated in many cases. Due to the lack of open datasets provided by companies, researchers compose learning-datasets on their own, thus merging applications from different sources”, explains Dr. Daniel Arp. “But, merging data from different sources, leads to a sampling bias: official app stores of smartphone manufacturers tend to have less problems with malware, whereas alternative sources usually offer less protection than these well-known stores. In consequence, we could demonstrate that state-of-the-art approaches tend to rely on the source of an app instead of learning actual malicious characteristics to detect malware. This is only one of many examples in our paper that showed how a subtle pitfall can introduce a severe bias and affect the overall outcome of an experiment.”
A Follow-Up from Prior Research in CYS
“The work of the Dos and Don’ts was a natural follow-up from some prior work we’ve done at King’s and published at USENIX Security 2019 in TESSERACT [2], a framework for eliminating experimental bias in malware classification tasks by performing time-aware evaluation with appropriate malware distribution at test time.”, Dr. Fabio Pierazzi explains. “Daniel and Konrad reached out to me and Lorenzo because they felt there was more to be explored, in terms of experimental bias, and that is how this successful collaboration originated.”
The paper presentation at USENIX Security Symposium can be watched here.
Ongoing Collaborations
From September 2022, Dr. Daniel Arp has been visiting King’s College London as well as University College London to collaborate with Dr. Pierazzi and Prof. Cavallaro on mitigating concept drift. Dr. Erwin Quiring is also collaborating remotely on making machine learning systems more secure in the malware domain against smart adversaries.
More KCL Research at USENIX Security 2022
The paper by Dr. Fabio Pierazzi was not the only one featured from the Cybersecurity Group at USENIX Security 2022. Dr. Kovila Coopamooto co-authored a work [3] on understanding and modelling user feelings about online tracking (more here), and Dr. Ruba Abu-Salma co-authored a work [4] focusing on security concerns of migrant domestic workers. Ruba also published a paper [5] at the co-located “USENIX Symposium on Usable Privacy and Security (SOUPS)”.
The difficulties of operating learning-based methods in cybersecurity is exacerbated by the need to operate in adversarial contexts. Understanding the perils this work outlines should raise awareness of possible pitfalls in the experimental design and how to avoid these – so the researchers hope.
References
[1] Daniel Arp, Erwin Quiring, Feargus Pendlebury, Alexander Warnecke, Fabio Pierazzi, Christian Wressnegger, Lorenzo Cavallaro, Konrad Rieck, Dos and Don’ts of Machine Learning in Computer Security, Proceedings of the USENIX Security Symposium, 2022 – Distinguished Paper Award
[2] Feargus Pendlebury, Fabio Pierazzi, Roberto Jordaney, Johannes Kinder, Lorenzo Cavallaro, TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time, USENIX Security Symposium, 2019
[3] Julia Słupska, Selina Cho; Marissa Begonia, Ruba Abu-Salma, Nayanatara Prakash, Mallika Balakrishnan, “They Look at Vulnerability and Use That to Abuse You: Participatory Threat Modelling with Migrant Domestic Workers”, Proceedings of the USENIX Security Symposium, 2022.
- There is also a digital privacy and security guide for migrant domestic workers created as part of the work presented in the paper: https://domesticworkerprivacy.github.io/.
[4] Kovila P.L. Coopamootoo, Maryam Mehrnezhad, Ehsan Toreini, “I feel invaded, annoyed, anxious and I may protect myself”: Individuals' Feelings about Online Tracking and their Protective Behaviour across Gender and Country, Proceedings of the USENIX Security Symposium, 2022
[5] Julia Bernd, Ruba Abu-Salma, Junghyun Choy, Alisa Frik, Balancing Power Dynamics in Smart Homes: Nannies' Perspectives on How Cameras Reflect and Affect Relationships, Proceedings of the USENIX Symposium on Usable Privacy and Security (SOUPS), 2022