Improving the world’s data commons
Investigating the provenance of Wikidata facts across languages at scale
Introduction
Wikidata is an openly accessible knowledge base that is built by a global community of volunteers. Since its launch in 2012 it reached more than 100 million items and 24,000 active editors (for more information see Wikidata statistics). Wikidata functions as the central source of information for a variety of projects in the Wikimedia ecosystem, including Wikipedia, a free, open content online encyclopaedia created through the collaborative efforts of a community of users also known as Wikipedians. Wiktionary is a dictionary available in over 151 languages written collaboratively by volunteers, it includes a thesaurus, a rhyme guide, phrase books, language statistics and extensive appendices. Finally, Wikisource is an online library that collects and stores previously published texts; including novels, non-fiction works, letters, speeches, constitutional and historical documents, and a range of other documents. There are also many other applications beyond this ecosystem, for instance intelligent assistants such as Siri and Alexa, and web search engines – Wikidata is feeding all these technologies to deliver truthful, up-to-date information to millions of people all over the world. Similarly, to Wikipedia, the scope of Wikidata is boundless, with topics as diverse as proteins, music, historical events, and space. Unlike Wikipedia though, Wikidata focuses on capturing factual information in a structured way rather than through text. The figure below shows a Wikidata claim with references.
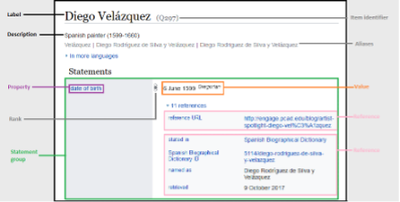
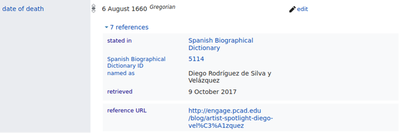
The more popular Wikidata gets, the more important it is to ensure its quality. Prof Elena Simperl, an academic working on sociotechnical data systems, explains: “Our research looks at making sure that a crowdsourced information resource such as Wikidata can be trusted by readers and developers. To gain people’s trust, you need to make sure that the data is accurate and that it is up to date and that it’s free of biases that can emerge by the choice of content or preferences of editors.” At this stage it is important to point out that Wikidata, just like Wikipedia, is a so-called secondary source – it records information originally presented somewhere else alongside the source where it comes from. This means that to understand the quality of Wikidata content, you also need to consider these sources. In Prof Simperl’s words, “the challenge is to come up with an algorithm that allows one to verify the quality of these references at scale, for millions of claims written in different languages.”
What exactly did the team do?
The team began by analysing the quality of Wikidata claims and references written in six languages. Prof Simperl explains what they meant by quality: “The community behind Wikidata have already put a lot of thought into defining what quality means to them when it comes to sources of information: it essentially boils down to authoritativeness – is it high-profile, credible, trusted source like a peer-reviewed academic journal or a post on social media – relevance – how relevant is the source to the actual claim? and accessibility - when you click on it, you should be able to see the information pertaining to the fact quickly rather than having to download some sort of massive spreadsheet and start processing it and extracting the one row you need”. Mr Gabriel Amaral, PhD student at KCL Informatics explains: “by including other languages beyond English we wanted to see if there was a difference in quality between languages”. This matters because there are communities managing different versions of Wikipedia in different languages and they may have developed other practices to work with references.
The team then investigated how the quality of Wikidata varies according to language and reference type. Evaluating how authoritative, relevant, and accessible Wikidata sources are, is by no means an easy task – some small parts of it, like checking if the link works can be automated, for the rest you need someone to actually go to the source and check it. That takes time and resources, so the team started thinking about using machine learning, with a human in the loop to be able to scale it to millions of claims. They created a system that first asks volunteers from an online crowdsourcing platform to assess some references by hand, and then uses their answers to train different machine learning models. The team then evaluated this system with Japanese, Portuguese, Swedish, Dutch, Spanish and English references. This multilingual aspect of the work was important to the team. As Dr Piscopo explains, Wikidata … “can enable people who don’t speak English to have access to good quality, trustworthy information, and our system offers a way to check references in multiple languages and facilitate that”.
The impact so far
The novelty of this work encompasses many layers, Mr Amaral explains, “besides the dataset we provide open source and the analysis into the current quality of references in those five languages, we have a tool which is available to download for free which tells you for claims in a certain language, or in different languages, in which data statements, which claims do not work, why they don’t work, which references don’t work and why, and what can be improved in references.” The work was published in the ACM Journal of Data and Information Quality, which you can access here. In April this year it received the Wikimedia Research of the Year Award, which recognizes recent research that has the potential to have significant impact on the Wikimedia projects or research in this space.


The work was funded through two European training networks, WDAqua (for Dr Piscopo), and Cleopatra (for Mr Amaral). We would also like to thank the Wikidata team and community for their feedback and support.